
SW
[데이터베이스] (2) 데이터베이스 관리시스템 본문
0. DBMS의 발전 배경
- DBMS
- DataBase Management System
- 데이터베이스를 관리해주는 소프트웨어
- 화일 중심 데이터 처리 시스템(System)
- 각 응용 프로그램이 논리적 화일 구조를 정의하고 직접 물리적 화일구조로 표현
- 각 응용 프로그램이 물리적 데이터 구조에 대한 접근 방법을 구현
- 각 사용자가 데이터와 이를 처리하는 프로그램을 모두 관리 유지
- 응용 간의 데이터 공용이 불가능
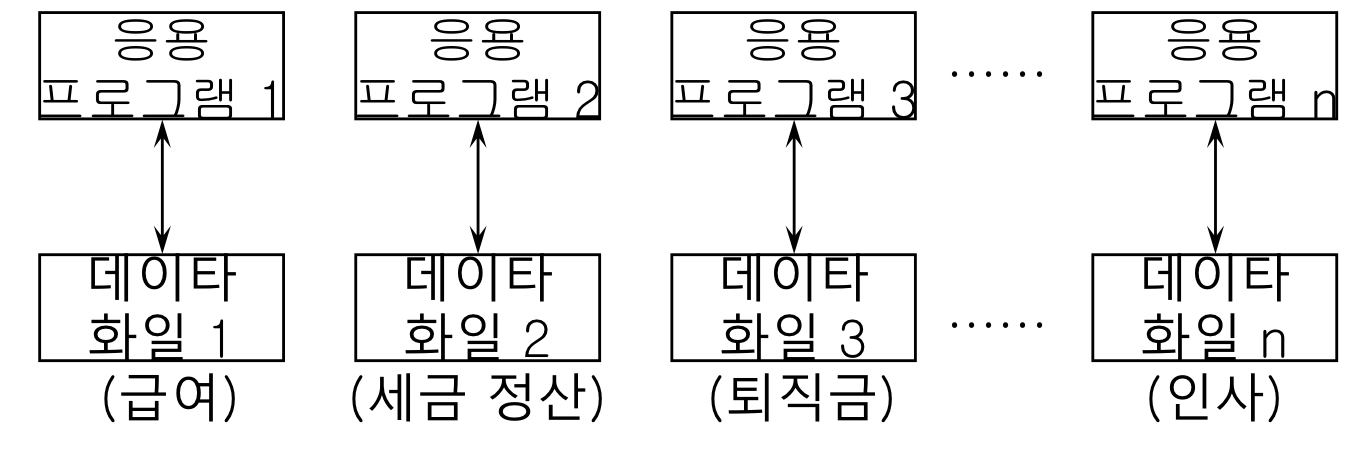
- 화일 시스템에서 응용 프로그램과 화일과의 관계
- 1:1 관계 => 데이터의 종속성(dependency)와 중복성(redundancy)을 야기
- 문제점 : 주소, 사원번호, 이름과 같은 것이 각 화일에 공통으로 들어가 있을 수 있음. 만약 하나의 프로그램에서 어떤 직원의 주소를 바꾸면 다른 부서에서 봤을 때 바뀐 주소를 볼 수 없음. 따로 관리하기 때문. => 일관성, 정확도가 떨어지고 중복이 되어있음.
- 데이터 종속성(Data Dependency)
- 응용 프로그램과 데이터 간의 상호 의존관계
- 데이터의 구성 방법이나 접근 방법의 변경 시 관련 응용 프로그램도 동시에 변경해야 됨
- 응용 프로그램 및 데이터 관리가 곤란
- 데이터 중복성(Data Redundancy)
- 한 시스템 내에 같은 내용의 데이터가 여러 화일에 중복 저장되어 관리
- 문제점
- 일관성(consistency) => 다른 부서에서 데이터를 바꿔도 다른 부서에서 바뀌지 않아 있을 수 있음.
- 보안성(security) => 다른 부서에서 볼 수도 있음.
- 경제성(economics) => update를 모두 해야해서 비효율적.
- 무결성(integrity) => 정확하지 못할 수 있음.
- 화일 관리 시스템(file management system)
- 데이터의 중복이나 종속성 문제를 다소 해결해주나 보안이나, 많은 사용자가 동시에 사용하는 경우에 대해서는 취약.
- 예를 들면, 영화예매를 할 때 두사람이 동시에 예매하면 문제가 생기는 경우

1. 데이터베이스 관리 시스템의 정의
- DBMS(Database Management System)이란?
- 응용 프로그램과 데이터 사이의 중재자로서 모든 응용 프로그램(사용자)들이 데이터베이스를 공용할 수 있게 관리해 주는 범용 소프트웨어 시스템
- 예) MySQL, PostgressQL, Oracle, SQL Server 등

2. DBMS의 필수 기능
- 정의(definition) 기능
- 하나의 저장 구조(storage structure)로 여러 사용자의 요구를 지원할 수 있도록 데이터를 조직(organize)하는 기능
- 범용성이 있는 소프트웨어이기 때문에 어떤 조직이 필요한 것인지 정의할 수 있어야 한다.
- 정의 기능의 요건
- 데이터의 논리적 구조(logical structure)를 명세
- 데이터의 물리적 구조(physical structure)를 명세
- 물리적/논리적 사상(mapping)을 명세
- 조작(manipulation) 기능
- 사용자와 데이터베이스 간의 interface를 위한 수단
- 체계적 데이터베이스 접근 및 조작: 검색(retrieve), 갱신(update), 삽입(insert), 삭제(delete)
- 데이터 언어(SQL)로 표현
- 사용하기가 쉽고 자연스러운 도구
- 원하는 연산의 명세 가능
- 효율적인 처리
- 제어(control) 기능
- 데이터의 정확성(correctness)과 보안성(security)을 유지하는 기능
- 제어 기능의 요건
- 무결성(integrity) 유지
- 보안(security), 권한(authority) 검사
- 병행수행 제어(concurrency control)
- 복구(recovery) => 비유하면, A가 B에 돈을 보냈는데 B가 돈을 못받았다고 하면 복구가능
3. DBMS의 장단점
- 장점
- 데이터 중복(redundancy)의 최소화
- 데이터의 공용(sharing)
- 일관성(consistency) 유지 => 동시접속자가 있더라도 일관성 유지
- 무결성(integrity) 유지 => 장애가 발생하더라도 정확성, 무결성 유지
- 보안(security) 보장
- 표준화(standardization) 용이 => SQL
- 기관 전체 데이터 요구의 조정
- 단점
- 운영비의 overhead => 데이터가 적을 때 굳이 사용할 필요는 없다.
- 복잡한 절차의 data backup과 recovery
4. 데이터 독립성
- 데이터 독립성(data independency)
- 논리적 데이터 독립성(logical data independency)
- 응용 프로그램에 영향을 주지 않고 논리적 데이터 구조의 변경이 가능
- 응용 프로그램의 효율적 개발이 가능
- 물리적 데이터 독립성(physical data independency)
- 응용 프로그램과 논리적 데이터 구조에 영향을 주지 않고 물리적 데이터 구조의 변경이 가능
- 저장 장치의 효율적 개발이 가능
- 논리적 데이터 독립성(logical data independency)
- 데이터 독립성 구현 기법
- 사상(mapping)

- A, B, C, D가 바뀌더라도 변하지 않도록 효율적으로 구현
- 이렇게 하나의 database로 존재하고 그것들이 논리적구조 사상으로 각 용도에 맞게 사용됨 => 중복성 문제 해결
5. DBMS의 발전 과정
- 제 1세대 DBMS(first-generated DBMS)
- IDS(Integrated Data Store)
- 최초의 범용 DBMS
- 1960년대 초에 Charles Bachman에 의해 설계
- 네트워크 데이터 모델(network data model)의 기초 => 개체들을 각 노드로 놓고 네트워크형태로 엣지를 만듦
- IMS(Information Management System)
- 1960년대 후반 IBM이 개발
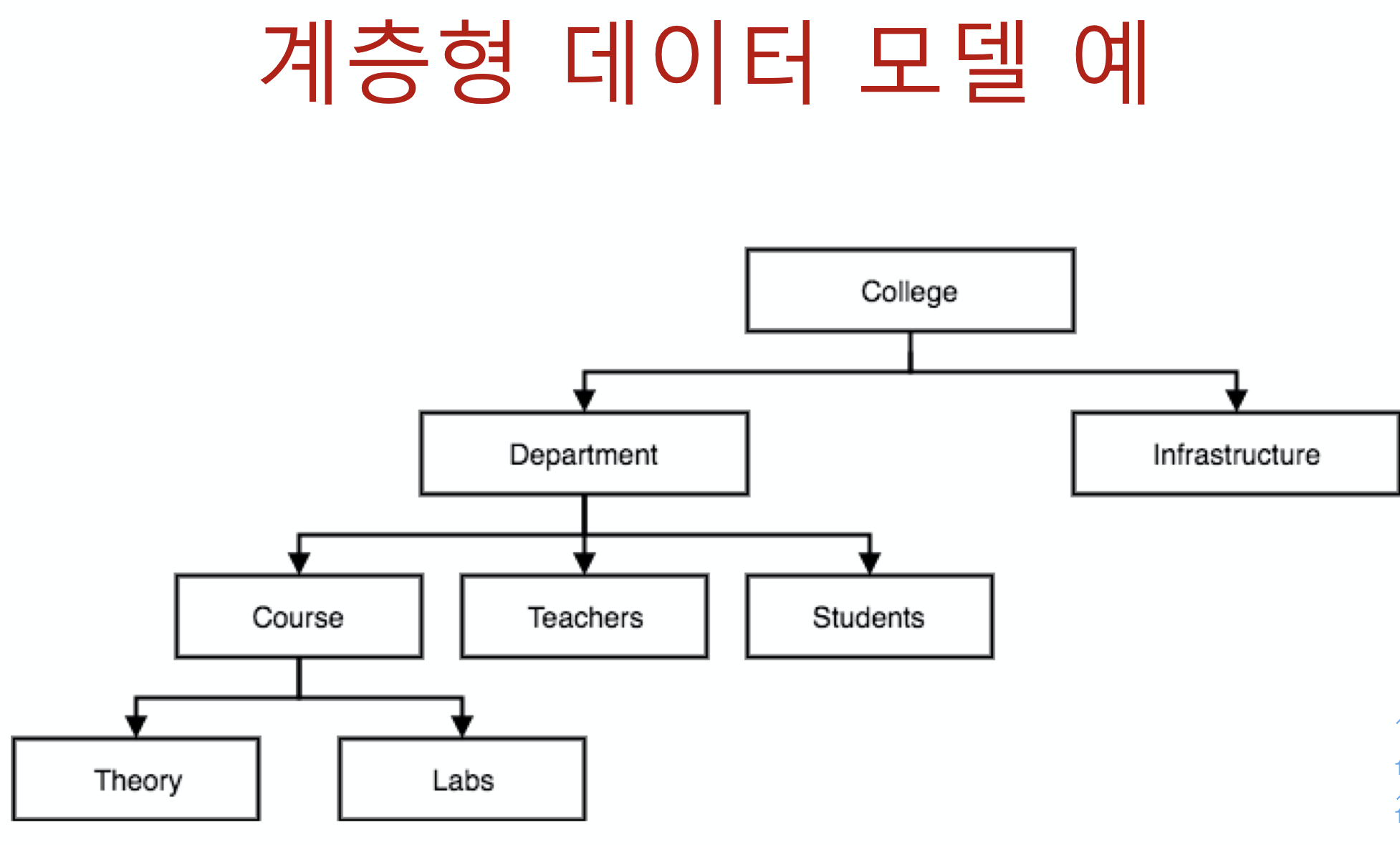
- 계층 데이터 모델(hierarchical data model)의 기초
- 1970년대 초에는 대형 컴퓨터 회사들이 DBMS를 자체 제작 판매
- IDS(Integrated Data Store)

- 제 2세대 DBMS : RDBMS
- 관계형 데이터 모델(relational data model)
- IBM의 Edgar가 제안
- 테이블 형태의 데이터 구조
- Relational Database 이론의 기초
- 1980년대부터 DBMS의 주류가 되었고 현재에도 가장 보편화됨
- OLTP(Online Transaction Processing : 실시간 일처리 서비스)의 강자
- SQL
- IBM이 관계 DBMS의 일부로 개발
- 세계 표준 데이터베이스 언어
- 주요 관계형 DBMS
- Oracle, MySQL, SQL Server, PostgreQL, IBM DB2, Microsoft Access, SQLite, MariaDB, Informix, Azure SQL
- 관계형 데이터 모델(relational data model)
- 제 3세대 DBMS
- 사용자의 데이터베이스 응용에 대한 복잡성(complexity) 증대
- engineering, images, videos, spatial, time series, data mining
- 사용자의 요구에 대처하기 위해 새로운 data model을 기반으로 시스템 개발
- 객체지향 DBMS(OODBMS: Object-Oriented DBMS)
- Object-oriented programming-basis
- 제 2세대 DBMS + 제 3세대 DBMS
- 객체 관계 DBMS(O-RDBMS: Object-Relational DBMS)
- 90년대 중반 이후 관심이 증가하였으나, 현재 점유율 측면에서 관계형 데이터베이스에 비해 크게 뒤떨어짐 => 응용에는 적합하지만 보편화되지 않음.
- 사용자의 데이터베이스 응용에 대한 복잡성(complexity) 증대
6. NoSQL
- NoSQL == Not Only SQL Databases
- SQL만을 사용하지 않는 DBMS => 관계형 DB를 사용하지 않는 다는 것이 아니라, 여러 유형의 DB를 사용한다는 것이다.
- Schema-less or flexible schema
- 각 레코드가 동일한 칼럼 즉, 동일한 구조를 가질 필요가 없음.
- No relationship
- 한 개체(문서)안에 모든 필요한 속성을 대부분 표현
- 데이터 중복을 허용
- De-normalized data
- 개체 간의 중요성이 중요하지 않은 응용
- 대용량 단위의 빠른 추가, 검색 및 조회가 중요한 응용
- 개체의 속성에 대한 업데이트(update)가 잦은 응용에는 적합하지 않음
- 응용 예 : Document data, Search Engine, Web log data, User-generated data, etc..
- NoSQL 종류
- Document Databases(Elasticsearch, MognDB, CouchBase...)
- Key-value stores(Dynamo DB, redis, Memcached...)
- Graph stores(Neo4j, AllegroGraph...)
'대학교 > BE' 카테고리의 다른 글
| [데이터베이스] (1) DB 환경 (0) | 2020.04.08 |
|---|---|
| [데이터베이스] 관계형 데이터베이스 (0) | 2020.04.03 |
| [데이터베이스] RDBMS 종류와 특성 (0) | 2020.03.19 |
| [Maven] Plug in (0) | 2020.03.17 |
| [Maven] 프로젝트 생성, 컴파일, 실행 (0) | 2020.03.17 |
'대학교/BE' Related Articles
more




Comments